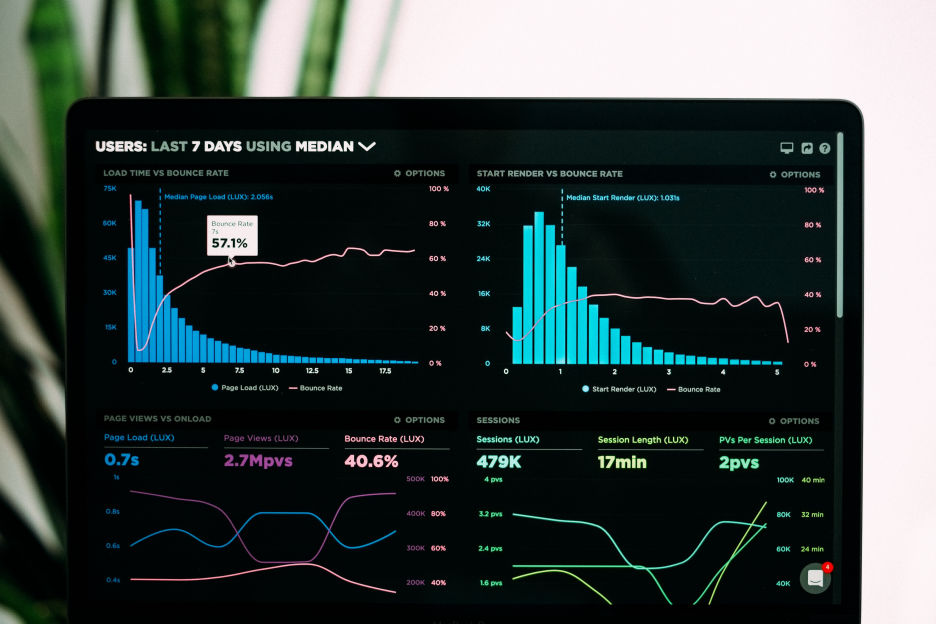
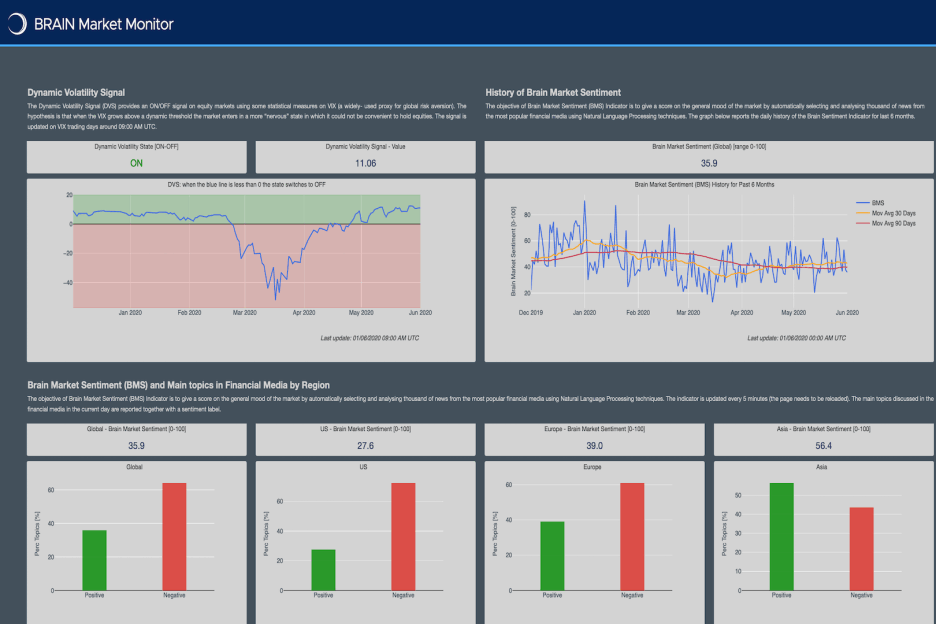
BRAIN DATASETS

BRAIN SENTIMENT
INDICATOR
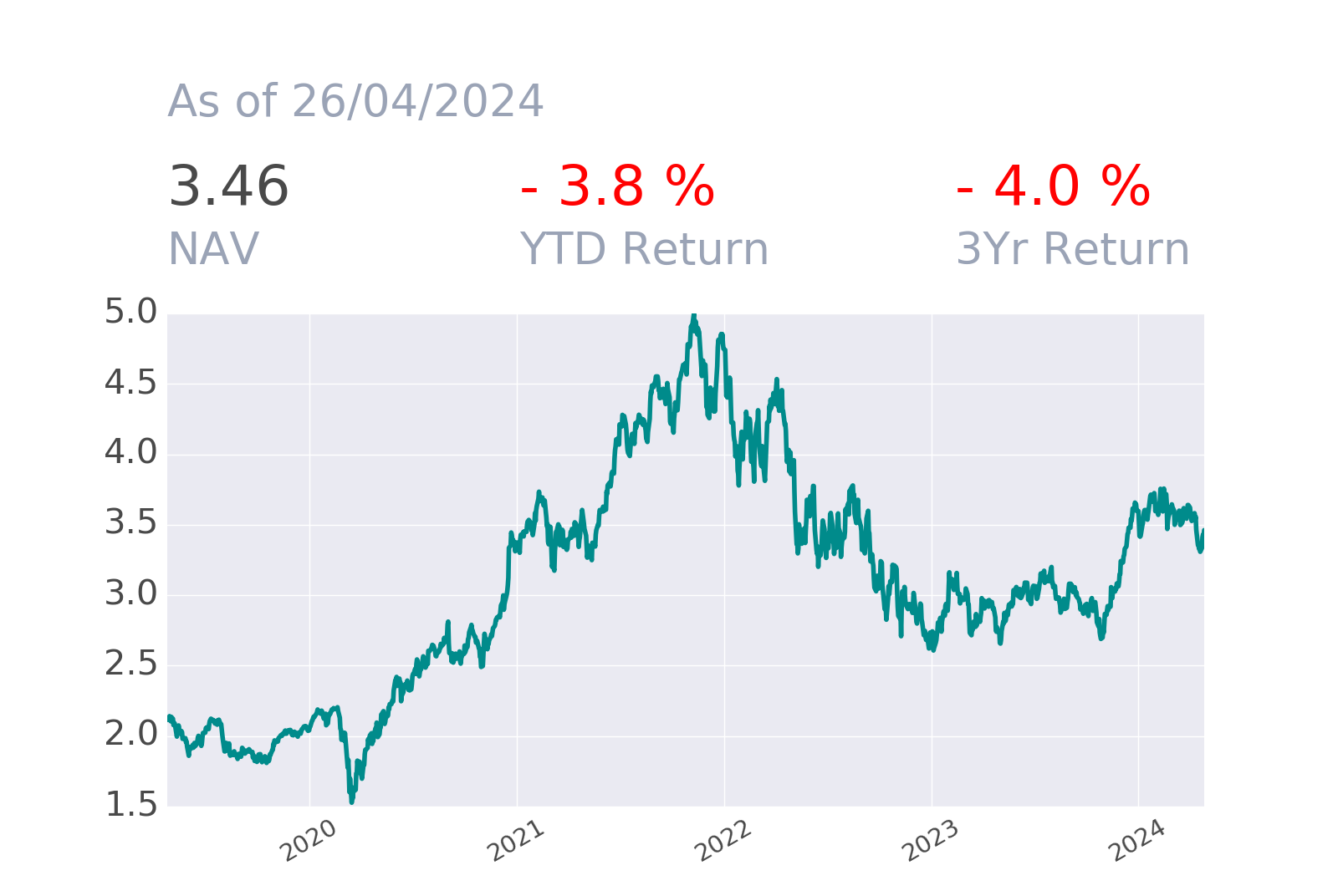
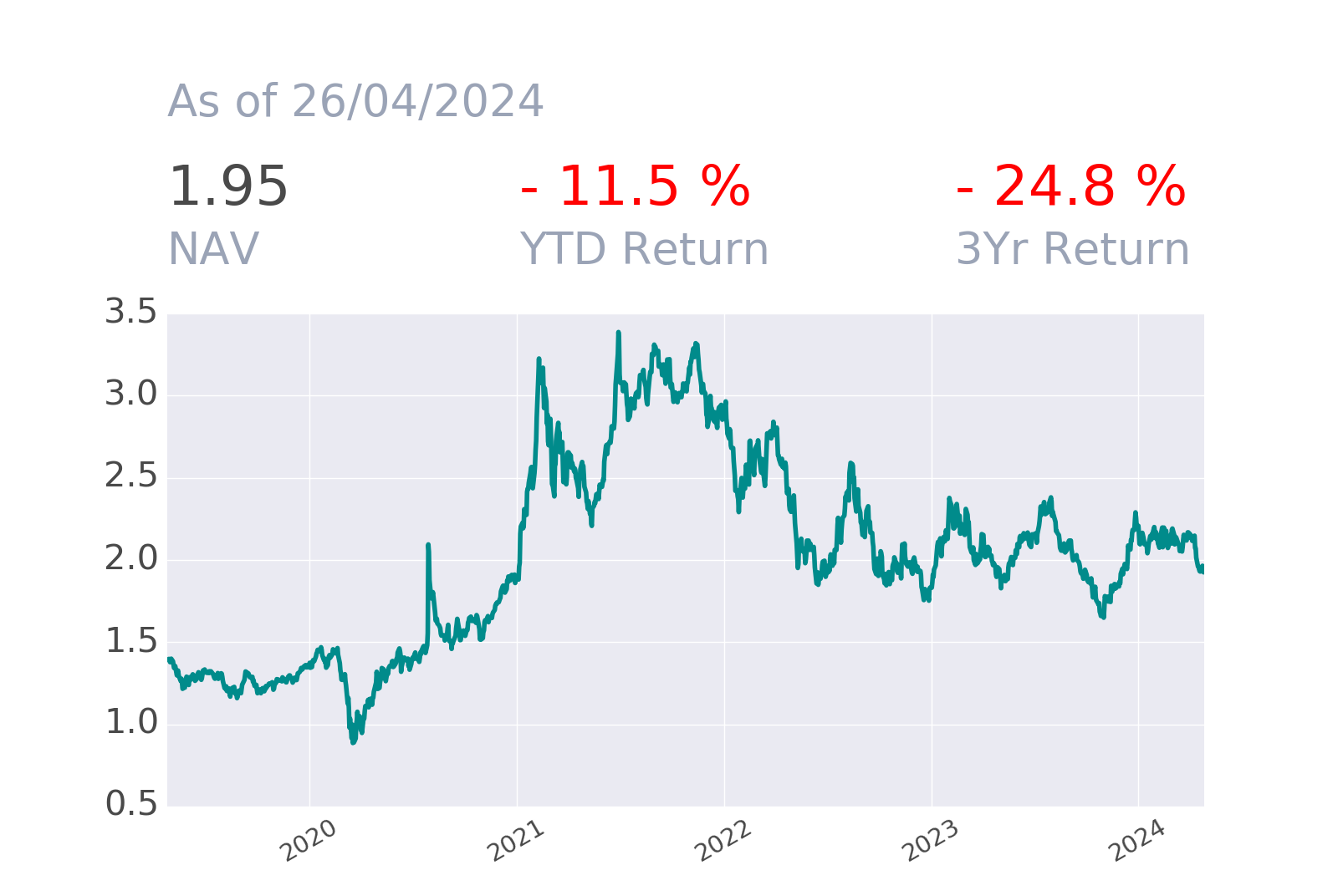
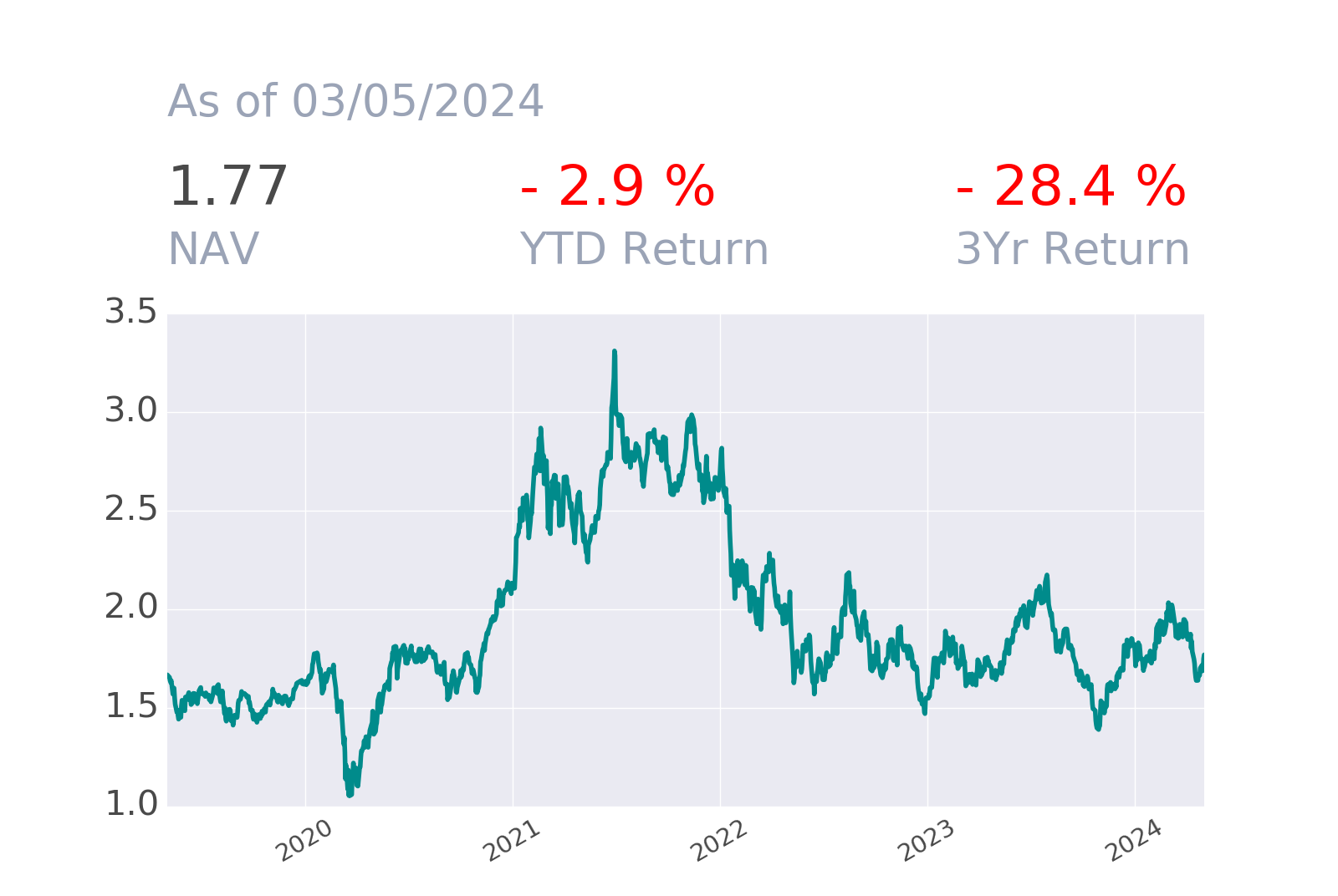
The Brain Sentiment Indicator (BSI) measures the “mood” on more than 10000 global stocks, major sectors, currencies, commodities and crypto based on the analysis of financial news using Natural Language Processing techniques and LLMs. As a trial we provide approximately five years of history for a subset of assets and upon request a 30 days access to the daily report corresponding to the full universe.

BRAIN MACHINE LEARNING STOCK RANKING
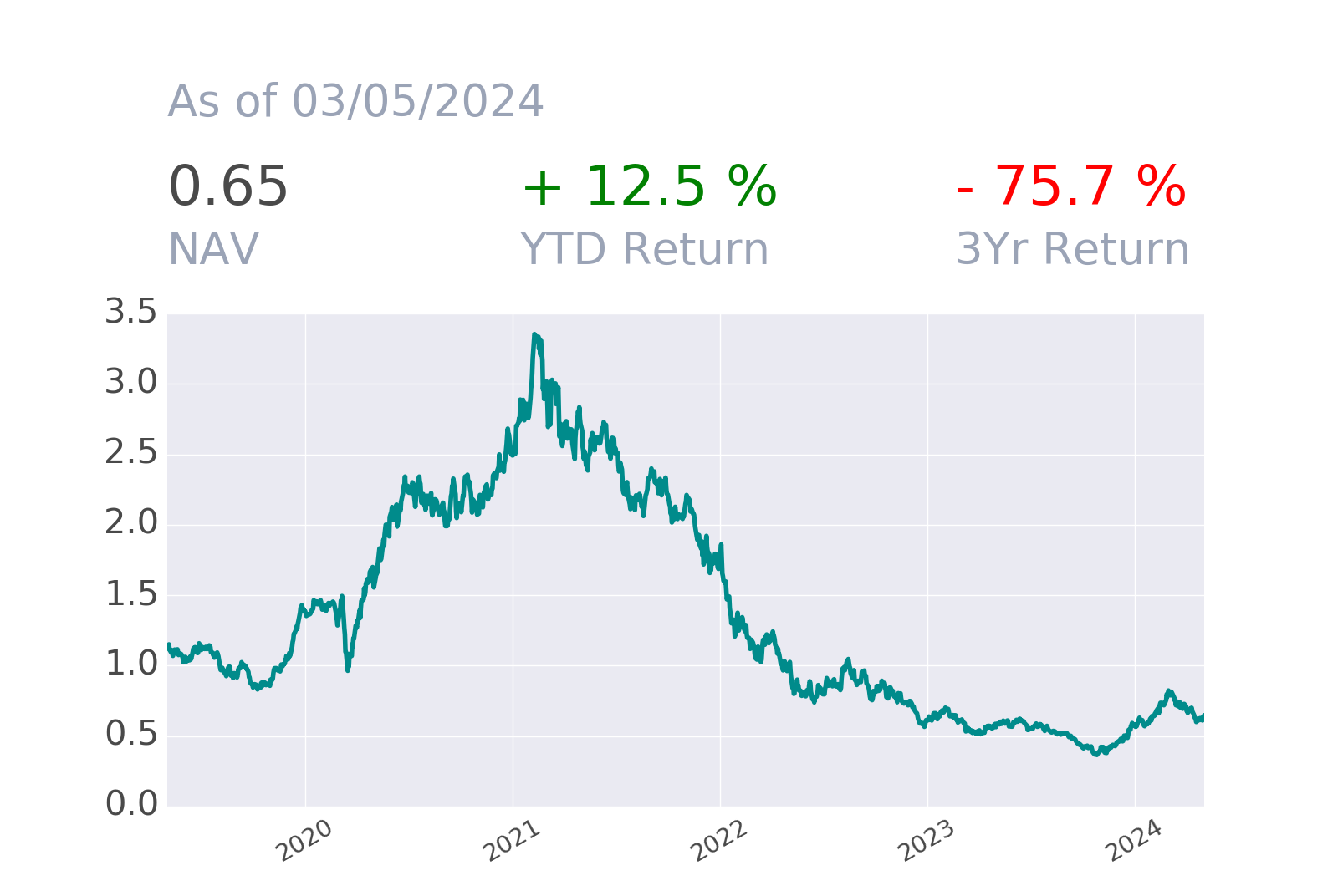
Brain Machine Learning proprietary platform is exploited to generate a daily stock ranking based on the predicted returns of a universe of the largest US and European stocks on four time horizons: 2, 3, 5, 10 and 21 days (other time horizons could be developed and tested upon request). The model implements techniques to reduce the well-known overfitting problem for financial data.